My brain hurts
Ok, I fucking hate QoS. I've taken a class on it, studied it, read the book...shit just drips out of my brain the second I'm not staring at it. It's like the ghost from mario; When you aren't looking it's trying to kill me.
* Congestion avoidance (WRED or WTD)
* Congestion management (queuing)
Now, Cisco recommends classification and markings be done "As close to the source as possible." Well, let me throw an ACL and match by IP address and mark these packets with the appropriate DSCP markings so that I can ensure my link isn't crushed by Candy Crush ©®℗™℠. But what about those links up to the L3 device? Those stupid ass L2 switches have their own queues and thresholds and other shit. If we only implement MQC..then we aren't deploying QoS "End-to-end." Shut up Cisco.
Now, I won't pretend to be an expert on this crap...even though I am technically certified as one. I hate QoS, did I mention that? Anyways, lets talk this thing out, friends.
Some basic points:
CoS (Class of Service) is L2
DSCP (Differentiated Service Code Point) is L3
There is a whole lotta stuff to talk about regarding these two points; how to convert the numbers from binary, what fields make up these numbers, etc. We can talk about those if we want...but a lot of those points are googlaable. One major point is that these values are by default not trusted..but we'll get back to that.
Now what makes up QoS:
* Classification
* What is it, and what it do.
* Do it as close to the edge as possible.
* Marking
* "Coloring" packets with a certain color to be identified as it flows through the network.
* Do it as close to the edge as possible.
We can classify and mark at L2 or L3..L2 would be using the CoS and L3 would be using DSCP. CoS markings are obviously lost if it goes over a L3 link...we can mitigate this by mapping the L2 CoS value to a L3 DSCP value. Once the traffic has been successfully marked, it can be accessible for QoS handling on the network!
Now that we know those basics..we have to actually find out the traffic on the network. You can use NBAR, Netflow, Cisco IP SLA, etc. The point is to learn what is on the network. I know of some people that swear by aproduct called [LiveAction](http://liveaction.com/), while others have used something called [Scrutinizer](https://www.plixer.com/Scrutinizer-Netflow-Sflow/scrutinizer.html).
Once you understand what is on the network, it is recommended to try and group this into differing QoS service classes. These classes are simply a logical grouping of packets that are to receive similar levels of applied quality. A service class can be as granular as that of a single user (MAC/IP address) or by application (Port number/URL). There are a number of service class templates to help facilitate the mapping, be it a 4- and 5-class model, 8-class model, or 11-class model..it really depends on how granular you wish to get. The most important note to make about these different service classes is that they are consistent. If you have a Voice service class with a DSCP marking of 46...you better use 46 everywhere in your environment (or good luck unraveling that shitball).
Now that we've discovered what is on the network we need to classify it and mark it appropriately so that it is correctly handled. Where and how we do this is up to the environment.
* You CAN mark L2 frames on a PC if the NIC supports it.
* You PROBABLY will mark at the Cisco phone for voice (if there is one) and reclassify or mark the incoming PC frames.
* You PROBABLY will accept the markings or remap at the access switch.
* You PROBABLY remap the CoS values to DSCP..or accept the L2 markings.
The above points are the QoS trust boundaries. By default...Cisco does not typically trust any markings. Why would they? Joe Shmoe could mark his own traffic as AF46 (The best service, typically)...so we would rather control where that point is configured.
*****
Remember why I hate L2 QoS? **The number of hardware queues available differ in each switch model, supervisor, and line card.** Some switches suck and ONLY support egress queuing..**cough 2960S cough**..so you have to know the capabilities of the switch. The queuing mechanism is represented as 1PxQyT. What the fuck did I just say? P=Priority queue, Q=Non-priority queues, T=Thresholds *per* queue. Now looking at the 3750 we have...we see that it has differing queuing mechanisms for input and output. For input, it has a **1P1Q3T ingress/Receive queue** and a **1P3Q3T Egress/Transmit queue.**
What is a priority queue? Well, it depends (Screw you QoS!!); Some switches (6500) service the priority queue whenever there is traffic in it...which may starve other queues. Some switches support one or more drop thresholds to a queue (like our 3750 example).
What happens in these queues is FURTHER made difficult...ugh! Our faithful 3750 uses SRR for both ingress/egress queues.
INGRESS IS ALWAYS SHARED WHILE EGRESS CAN BE EITHERendrant. The 6500 uses WRR AND SRR...depending on the supervisor and line card.
Once we know the capabilities of the particular switch..we can start prioritizing traffic by placing packets with particular DSCP or CoS values into certain queues and threshold values. When supported, the threshold values can be used to set the point where the switch congestion avoidance mechanisms will start to drop that traffic.
Now that we know the 3750 has a total of
2 ingress queues (1 priority and 1 non-priority) and 3 thresholds per queue...we can start carving it out!
WTF is a threshold? It ultimately all comes down to port with a finite buffer space, broken out into independent queues, or figurative lines the incoming frames must wait in. We have to identify the cutoff point on those individual lines in which to start tail dropping traffic.
What percentage/ratio is assigned to each independent queue is determined by the
mls qos srr-queue input buffers <queue#1> <queue2> global command. Using
mls qos srr-queue input buffers 90 10 as an example, queue 1 has 90% of the available buffer space, while queue 2 has 10%.
Queue 2 is the priority queue by default! Furthermore, we can identify the bandwidth amount per queue! We do this by using the global command: mls qos srr-queue input bandwidth <queue1> <queue2>. Furthermore, we can specify the priority queue bandwidth amount with the global command mls qos srr-queue input priority-queue <#> bandwidth <%>. An example configuration of this could be "mls qos srr-queue input bandwidth 70 30" and "mls qos srr-queue input priority-queue 2 bandwidth 30."
If the potential maximum is 100% of a threshold until traffic starts dropping for the independent queues, thresholds can be identified with specific CoS/DSCP mappings. To expand on this, you can map certain values to a queue with different thresholds. For example, the global command
mls qos srr-queue input cos-map queue 1 threshold 1 0 1 2 would map the cos of 0, 1, and 2 to queue 1 threshold 1 and
mls qos srr-queue input cos-map queue 2 threshold 1 4 5 would map the cos of 4 and 5 to queue 2 threshold 1. ALL THIS IS DOING IS ASSIGNING THE COS VALUES TO THE RESPECTIVE QUEUES AND IDENTIFYING THE QUEUE THRESHOLD!
ANOTHER Important note:
You can configure SRR on egress queues for sharing or shaping. However, for ingress queues, sharing is the default mode, and it is the only mode supported. Shaped mode guarantees bandwidth and rate limnits to that amount. Inversely, shared mode guarantees bandwidth but can utilize unused bandwidth assigned to other queues. Ultimately, shared round robin is a minimum bandwidth guarantee.
EXAMPLE TIME!!!
Now using the following cos-maps...
mls qos srr-queue input cos-map queue 1 threshold 1 0 1 2
mls qos srr-queue input cos-map queue 1 threshold 2 3
mls qos srr-queue input cos-map queue 1 threshold 3 6 7
mls qos srr-queue input cos-map queue 2 threshold 1 4 5
Since this is an
INGRESS queue, we are using SHARED mode SRR. To reiterate, that means that all of the queues (all 2 of the ingress queues) can utilize the available bandwidth presented to them.
Using the line analogy, we've essentially created 2 lines (queues) with different lengths (thresholds) in which they can grow before management starts kicking people out.
Now what about the egress queue?
The concepts are IDENTICAL, with the exception being that egress queues use shaped mode over shared mode, which guarantees bandwidth and rate limits to that amount. Being that it is shaped mode, we can configure threshold limits! Furthermore, each port supports four egress queues, one of which (queue 1) can be the egress expedite queue. These queues are assigned to a queue-set. All traffic exiting the switch flows through one of these four queues and is subjected to a threshold based on the QoS label assigned to the packet.
The switch uses a buffer allocation scheme to reserve a minimum amount of buffers for each egress queue, to prevent any queue or port from consuming all the buffers and depriving other queues, and to control whether to grant buffer space to a requesting queue. The switch detects whether the target queue has not consumed more buffers than its reserved amount (under-limit), whether it has consumed all of its maximum buffers (over limit), and whether the common pool is empty (no free buffers) or not empty (free buffers). If the queue is not over-limit, the switch can allocate buffer space from the reserved pool or from the common pool (if it is not empty). If there are no free buffers in the common pool or if the queue is over-limit, the switch drops the frame.
Lets pretend we have the following configuration...
mls qos srr-queue output cos-map queue 2 threshold 1 2
mls qos queue-set output 1 buffers 15 30 35 20
mls qos queue-set output 1 threshold 2 40 70 90 400
What are we doing?
Well, lets break each one out (remember, this is going to be very similar to the input queue).
mls qos srr-queue output cos-map queue 2 threshold 1 2
Here, we're simply mapping the cos value of 2 to queue 2, threshold 1 (3 per queue).
mls qos queue-set output 1 buffers 15 30 35 20
Each threshold value is a percentage of the queue’s allocated memory, which you specify by using the mls qos queue-set output qset-id buffers allocation1 ... allocation4 global configuration command. The sum of all the allocated buffers represents the reserved pool, and the remaining buffers are part of the common pool. In this example, 15% for queue 1, 30% for queue 2, 35% for queue 3, and 20% for queue 4 (15+30+35+20=100).
mls qos queue-set output 1 threshold 2 40 70 90 400
This is where the egress queue gets squirrely. What do these values mean? We're saying that the threshold values for queue 2 are as follows: 40% for threshold1, 70% for threshold2, 100% for threshold3 (non-configurable), 90% for reserved, and 400% maximum.
Well, that was confusing as shit.
Another example to help drive it home with a look at queue 2:
mls qos srr-queue output cos-map queue 2 threshold 2 4
mls qos srr-queue output cos-map queue 2 threshold 3 6 7
mls qos queue-set output <1/2> threshold 2 40 70 90 400
When the buffer is filled with 70% of traffic it will start dropping traffic with cos 4 and not traffic with cos 6 or 7 because it's mapped to thresshold 3 (=100%)
But what about the reserved and max?
[buffer size:
mls qos queue-set output 1 buffers 15 30 35 20
mls qos queue-set output <1/2> threshold 2 40 70 90 400
If you take for example queue 2, we configured 90% as reserved. So you reserve 90% of the buffer size of queue 2 (which was 30% of the total buffer space). So out of a theoretical 100%, we gave 30 of that to queue 2. Of that 30 %, we configured 90% as reserved.
The remaining 10% from queue 2 is seen as common buffer space. Can be used by queue 1, 3, 4
Max reserved means, how much it may expanded and use buffer space from the common pool buffer space as explained above. Of that 10% that is not reserved...it can be used to service the other queues.
Helpful show commands:
show mls qos: This will show you if QoS is enabled!
show mls qos queue-set: This will show you the queue-sets configured for the output queues.
show mls qos input-queue: This will show the configured buffer, bandwidth, priority%, and threshold values for the different queues.
Also, what is the queue-set number meaning? 1 is default...AKA you don't have to configure anything. You CAN configure a queue-set 2, but it will require interface-level configs (
queue-set 2) to use. Having more than 1 could simply allow for more granularity.
Interface level configs:
interface giX/X/X
priority-queue out - Enables the priority queue; The expedite queue is a priority queue, and it is serviced until empty before the other queues are serviced.
mls qos trust device cisco-phone - Extends the trust zone to the phone.
mls qos trust dscp - Trusts the DSCP value; By default the DSCP value is not trusted.
srr-queue bandwidth share 1 30 35 5 - Here we are saying 1. Ignore queue 1's SRR sharing weight as this is the priority queue. Furthermore, were allocating 30% to queue 2, 35% to queue 3, and 5% to queue 4. Because we said share, the other queues can use bandwidth from other queues if under congestion.
Policing: The point I want to notate is the amount + the burst. Kevin Wallace explained this better than anyone I've ever heard: The specified rate is an AVERAGE. Think of it as intercity traffic; you go as fast as you can, until you cant. The rate is TECHNICALLY the speed limit, but you go as fast as the traffic allows. While the speed is the line rate, the amount that goes is the burst rate (why it is in bytes not kbps, mbps, etc).
- Optimally deployed as ingress tools as they make instantaneous send/drop decisions.
- Do NOT delay traffic, they simply check the traffic and make a decision.
- When supported, markdowns should be done according to standards-based rules (AFX1 to AFX2 for example).
Shaping: Uses buffers to smooth out spiking traffic flows for later re-transmission.
- Only applied as egress tools.
- Objective is to NOT drop the traffic.
- Excess traffic is buffered and delayed until the offered traffic dips below the defined rate.
- Real-time traffic should be shamed to 10ms intervals. Since tc cannot be manipulated directly, use the formula Tc=Bc/CIR. For example, if we have a 1Gbps link that we wish to shape to 120Mbps with 10ms intervals..how much data should go per interval? If we wish to have 10ms intervals, then there will be 100 intervals per second (1000/10ms). That would mean that we'd need to have a Bc value of 1.2 Mbps. So for every interval, 1.2 Mbps will be sent at a time interval of 10ms.
ASIC+Buffer: The buffer amount is shared per ASIC. The number of ports per ASIC is dependent on the hardware version of the switch. The 2960S, for example, has 2 ASICs..or 24 ports per ASIC. This can be identified by performing a
show platform pm if-numbers; The first number in the port column identifies the asic/X. For example, 0/X would represent a port that is in ASIC 0 and 1/X would represent a port that is in ASIC 1. In an ideal world, we'd split traffic across the ASICs by connecting some hosts on the first set of 24 ports and some on the other set of 24 ports, to best utilize the buffer memory.
Buffer vs Bandwidth? The biggest thing to know is that if its a 100Mb connection or a 10Gb connection...the transfer rate is still the same: How fast electricity is sent over copper. That being said, what makes a 1Gb or 10Gb connection different? The difference is the rate in which the scheduler can service the queues. When we allocate bandwidth, we're essentially allocating a weighted value to how often the scheduler will service the queues. When we reference the buffer, we're telling the hardware how much memory to allocate to the queues.
Buffer notes:
- Give every queue at least 10 % buffer space with a thresholds of 40 %.
- Setting thresholds too high may result in one highly congested port stealing buffer memory from all the other ports.
- If every queue reserves the maximum possible very little will be left in the common buffer pool.
- If a queue doesn’t reserve anything it may be starved by the other queues/ports.
Dropping: Tail drop or random drop
- Tail drop is used by both policing and shaping; when the traffic exceeds a certain rate, every packet is dropped until traffic drops below that rate. This has adverse effects on TCP re-transmission.
- Random drop is a tool that randomly (go figure) drops packets in an effort to drop packets to AVOID congestion that may lead to tail dropping. This works more closely with TCP retransmission logic.
- Best used to regulate TCP-based data traffic...sucks for real-time traffic.
Input:
Cisco 3750
- Queuing:
- 1 Priority queue, 1 non-priority queue, and 3 thresholds per queue (1P1Q3T)
- Queue 2 is the priority queue by default.
- Buffer:
- We specify the input buffer ratio with the following command: mls qos srr-queue input buffers <queue1> <queue2>.
- Bandwidth:
- SHARED round robin. This is applied globally. Shared means that its a MINIMUM bandwidth guarantee. Should other queues need additional bandwidth and it is available, they can "share" the bandwidth. Only in times of congestion does the bandwidth guarantee take place.
- We can specify the bandwidth amount for both queues: mls qos srr-queue input bandwidth <queue1> <queue2>.
- We can specify the bandwidth specifically to the priority queue: mls qos srr-queue input priority-queue <#> bandwidth <%>
Output:
Cisco 3750
- Queuing:
- 1 Priority queue, 3 non-priority queues, and 3 thresholds per queue (1P3Q3T)
- Queue 1 is the priority queue by default.
- Buffer: We specify the output buffer ratio with the following command: mls qos queue-set output 1 buffers <queue1> <queue2> <queue3> <queue4>.
- The egress buffer is shared PER ASIC.
- Bandwidth:
- SHAPED or SHARED round robin. This is applied at the interface level. Unlike shared that is a minimum guarantee, shaped is a MAXIMUM bandwidth guarantee. In other words, it gets a reserve portion of a port's bandwidth, and no more.
- We can specify the bandwidth amount for all 4 queues...AT THE INTERFACE LEVEL!
- srr-queue bandwidth share weight1 weight2 weight3 weight4. This specifies the weighted values for shared mode. These weights do NOT have to equal 100% They are weighted values. For example, if we had the weights 100 100 100 100, we'd have a total of 400. We'd essentially be giving each queue a weighted value of 100/400, or 25%.
- srr-queue bandwidth shape weight1 weight2 weight3 weight4. This specifies the inverse of the weight (1/weight) to determine the bandwidth for a queue. For example, the weight values 50 50 0 0 applied to a 1Gbps interface would mean 1/50th of the bandwidth of the 1Gbps link..or ~20Mbps. A value of 0 means...do not shape..or in other words..NO LIMIT--WOOHOOO!!!!
- If an interface has BOTH shaping and sharing...the shaped mode configuration is applied.
- srr-queue bandwidth limit weight can be used to specify the max amount of an interfaces bandwidth that can be used for outgoing traffic. By default, there is no limit (i.e. a weight of 100). AT THE INTERFACE LEVEL.
Scenarios:
1. We want to limit inbound traffic to 50 Mbps on a 1Gbps link. We could/should use a policer. We cannot used shaped round robin, as this is only available on egress interfaces.
2. We want to limit outbound traffic for a particular queue to 40 Mbps. We could use shaped round robin.
Practical implementation:
- Classify traffic as close to the trust boundary as possible.
- Use class-maps to match the traffic types (Can use L3 addressing, L2/L3 markings, ports, or specific protocols).
- Default class-map treatment is match-all.
- NBAR (match protocol) is more CPU intensive than by matching traffic by DSCP, addresses, or ACLs.
- Marking of traffic entails writing a value in the frame or packet header to document the class of traffic the packet has been determined to belong to.
- If the packet markings are not trusted, they are re-marked to a DSCP value of 0.
- By default trusting COS causes the DSCP value to be rewritten to the corresponding value based on the cos-dscp map.
- Marking is often done at the end device for Cisco voice and video products.
- Class-based marking occurs after classification. Therefore, if used on an output policy the packet markings can be used by the next hop-node to classify the packets but cannot be used on this node for classification purposes. If class-based markings are used on an ingress interface as an input policy, the markings applied to the packet can be used on the same device on its egress interface for classification purposes.
- If you apply an output policy to tunnel interface, the marking is applied to the inner packet header.
- If you apply an output policy to the physical interface, the marking is applied to the output packet header.
- Mark voice traffic EF (DSCP 46).
- Broadcast video should be marked to CS5 (DSCP 40).
- Real-time interactive traffic should be marked to CS4 (DCSP32).
- Multimedia conferencing should be marked to the AF4 class (AF41, 42, or 43..or DSCP 34, 36, or 38, respectively).
- Multimedia streaming should be marked to the AF3 class (AF31, 32, 33 or DSCP 26, 28, 30, respectively).
- Transactional data (excessive latency in response times directly impacts user productivity--low-latency) should be marked to the AF2 class (AF21, 22, 23 or DSCP 18, 20, 22, respectively).
- Bulk Data (High throughput data service--non-interactive background data applications) should be marked AF1 class (AF11, 12, 13 or DSCP 10, 12, 14, respectively).
- Best Effort should be marked DF (DSCP 0)
- Scavenger Should be marked to CS1 (DSCP 8).
- Network control should be marked to CS6 (DSCP 48).
- Signaling should be marked to CS3 (DSCP 24).
- Use set dscp and set precedence, as using set ip dscp only matches IPv4 and not IPv6.
- Voice should be admission controlled.
- Examples: G.711 and G.729a VoIP calls
- Broadcast video should be admission controlled.
- Example: Cisco IP Video Surveillance (IPVS), Cisco Digital Media Players (DMPs).
- Real-time interactive should be admission controlled.
- Example: Cisco TelePresence.
- Multimedia conferencing should be admission controlled.
- Example: Cisco Unified Personal Communicator, Cisco Unified Video Advantage, etc.
- Multimedia streaming MAY be admission controlled.
- Example: Cisco Digital Media System VoD streams.
- Transactional data should be treated with an AF PHB, with a guaranteed-bandwidth queue and DSCP-based WRED.
- Examples: Database applications, data components of multimedia collaboration applications.
- Bulk data should be treated with an AF PHB, provisioned with a guaranteed-bandwidth queue and DSCP-based WRED.
- Usually provisioned in a moderately provisioned queue to provide a degree of bandwidth constraints during periods of congestion.
- Examples: FTP, email, backup operations, etc.
- Best effort should be provisioned with a dedicated queue and may be provisioned with a guaranteed-bandwidth allocation and WRED/RED.
- Scavenger class should be assigned to a minimally provisioned queue.
- Examples: iTunes, YouTube, BitTorrent, etc.
- Network control traffic may be assigned a moderately provisioned guaranteed-bandwidth queue.
- Examples: EIGRP, OSPF, BGP, HSRP, IKE, etc.
- Signaling may be assigned to a moderately provisioned guaranteed-bandwidth queue.
- Examples: SCCP, SIP, H.323, etc.
CBWFQ notes:
- Use fair-queue presorter within a policy-map to manage fairly multiple flows contending for a single queue. Without using the fair-queue policy-map configuration, the default is FIFO. What does this mean? By "fair queuing," we create "mini" queues within the queue, per session. As seen on the right, the top picture indicates fair-queuing while the bottom one indicates FIFO. With fair-queue, the router will give each "mini queue" equal shares of the allocated bandwidth. Ultimately, the goal is to ensure that low volume talkers are not starved out of bandwidth by higher volume talkers.
- 64 configurable queues.
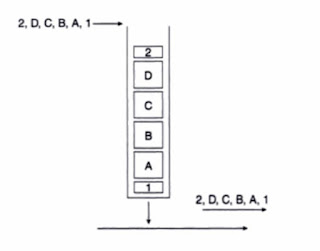
- Each queue is serviced in a weighted round robin (WRR) fashion based on the bandwidth assigned to each class. The CBWFQ scheduler then forwards packets to the Tx-Ring.
- Do NOT exceed 33% of the link capacity for the priority queue--you may starve other classes. IF there are links dedicated to a particular traffic type...ignore this rule.
- LLQ includes an implicit policer; a MAXIMUM bandwidth allocation.
- Allocate at LEAST 25% of link bandwidth for the default class; Unclassified applications end up here.
Congestion avoidance: Work BEST with TCP-based applications because selective dropping of packets causes the TCP windowing mechanism to throttle back and adjust the rate of the flows to manageable rates.
- Little impact on UDP..as no retry logic.
- Random early detection (RED): Randomly dropping of packets before it is all done at once (tail dropping) stops global synchronization of TCP streams.
- Weighted random early detection (WRED--WHAT CISCO USES): Uses AF drop preference values to drop packets more aggressively if it has a higher AF drop precedence. This is configured by using random-detect dscp-based. Do not configure WRED on the LLQ, but should generally be used whenever the feature is available. If you configure WRED on a policy map, make sure that it is not configured at the interface level.















